Datenanalyse: Wie unterscheiden sich die Quellen in Perplexity.ai von denen in der Google-Suche?
Du bist, wer du bist, zu einem erheblichen Teil wegen Google. Vielleicht hast du, als du jung warst, nach Berufsbildern gesucht und dabei etwas über die Arbeit in HR-Abteilungen oder im Marketing erfahren, hast dann nach passenden Ausbildungsstellen oder Studiengängen gegoogelt und arbeitest deshalb heute da, wo du arbeitest; vielleicht hast du deine Partnerin oder deinen Partner gefunden, weil du 2007 „Online-Dating“ gegoogelt hast; vielleicht hast du mit Google nach alten Freunden gesucht oder nach Verwandten, die du lange nicht gesehen hast und vielleicht hat euch das wieder zusammengeführt. Vielleicht hast du auch eines Tages einen ungewöhnlichen Knubbel an einer Stelle deines Körpers entdeckt und bist dank Google eher früher als später zum Arzt gegangen.
20 Jahre lang war die Google-Suche aus dem Leben der meisten Menschen nicht wegzudenken und ich glaube, das neigt sich dem Ende zu. Seit etwa einem Jahr nutze ich eine Suchmaschine mit dem Namen Perplexity.ai. Perplexity nimmt Fragen in natürlicher Sprache entgegen, greift wie klassische Suchmaschinen auf einen Index an Quellen zurück und beantwortet mithilfe dieser Informationen und dem im Sprachmodell erfassten Wissen meine Suchanfrage. Mit SGE und ChatGPT haben Google und Bing in den vergangenen Monaten ähnliche KI-Produkte an den Start gebracht. Perplexity gefällt mir persönlich am besten. Das enorme Wachstum zeigt, dass ich damit nicht alleine bin. Viele sehen das Start-Up als einen möglichen Google-Killer.
Was passiert mit meinen Rankings?
Was also wenn „Googeln“ wirklich bald Geschichte ist? Für viele Marketer und Unternehmer ist das eine sehr unangenehme Vorstellung, schließlich haben sie teils Jahre in SEO investiert. Mich persönlich würde folgende Nachricht erleichtern: Wer in Google hohe Rankings erzielt, hat gute Chancen, auch in der KI-Suche als Quelle aufzutauchen. Dann bliebe nur noch die Frage, wie viel qualifizierten Traffic das am Ende wirklich bringt.
Online gibt es rege Diskussionen über die Funktionsweise von Perplexity. Offiziell nutzt Perplexity einen eigenen Crawler, den PerplexityBot, der tatsächlich regelmäßig auf Webseiten vorbeischaut. Allerdings berichten viele Nutzer auf Reddit, dass die Quellen für zahlreiche Suchanfragen in Perplexity und Google identisch sind. Auch über die Architektur von Perplexity wird viel diskutiert. Immer wieder lese ich den Vorwurf, Perplexity würde die Suchergebnisse aus Google einfach mit einem Sprachmodell erweitern und den Menschen somit eher eine Innovation vorgaukeln, als tatsächlich eine zu liefern.
Ich habe mir deshalb die von Perplexity genutzten Quellen in einer eigenen Datenanalyse angesehen und sie mit den Top-Suchergebnissen in Google verglichen. Soviel vorweg: Eine Google-Kopie ist Perplexity nicht.
Datenanalyse: Methode
Um die Quellen vergleichen zu können, brauchte ich zunächst eine Art Grundwahrheit. Hierfür habe ich aus dem Kopf eine möglichst breite Auswahl verschiedener Suchkategorien zusammengetragen. Herausgekommen sind Themen wie „Unterhaltungselektronik“, „Marketingdienstleistungen“, „Politik“, „Natur“ oder „Wissenschaft“. Für jede dieser Kategorien habe ich mir anschließend Basis-Keywords bzw. -Suchanfragen ausgedacht, insgesamt zehn je Kategorie. Hiermit hatte ich nun natürlich einen Bias eingeführt. Um diesen ein wenig zu mildern, habe ich für jedes der Basis-Keywords tatsächliche Suchanfragen aus dem Google-Keyword-Planner und von answerthepublic.org gesammelt. Diese entsprechen dem, was Menschen tatsächlich suchen. Aus den gesammelten Daten habe ich im Zufallsverfahren für jedes Basis-Keyword jeweils zehn dieser Suchanfragen ausgewählt. Insgesamt konnte ich somit 1.800 Suchanfragen über 18 Kategorien analysieren.
Nutzt Perplexity dieselben Quellen wie Google?
Tatsächlich nutzt Perplexity zu einem großen Teil dieselben Quellen wie Google für seine Top-Suchergebnisse (fünf höchste Platzierungen). Das sind gute Neuigkeiten für alle, die in der Vergangenheit viel Arbeit in SEO gesteckt haben. Über alle Suchkategorien hinweg beträgt die Übereinstimmung der Quellen 64 %. Wenn man also hoch in Google ranked, stehen die Chancen gut, auch in Perplexity als Quelle aufgeführt zu werden.
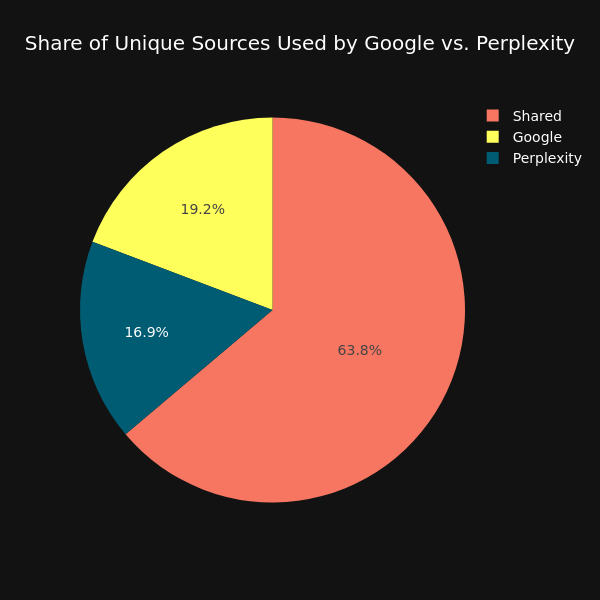
Die Übereinstimmung unterschied sich dabei je nach Kategorie. Die geringste Übereinstimmung habe ich für Suchanfragen zum Thema „Marketingdienstleistungen“ gefunden. Hier lag sie bei 46 %. Bei Suchanfragen zum Thema „Politik“ war sie mit 76 % am höchsten. Mit vorschnellen Interpretationen sollte ich angesichts der guten, aber doch recht kleinen Datenbasis natürlich vorsichtig sein. Hätte man mich vor der Untersuchung aber gefragt, in welchen Kategorien ich die höchste Übereinstimmung erwarte – ich hätte auf sensible Themen getippt. Politik gehört in den Augen vieler Menschen sicherlich dazu.

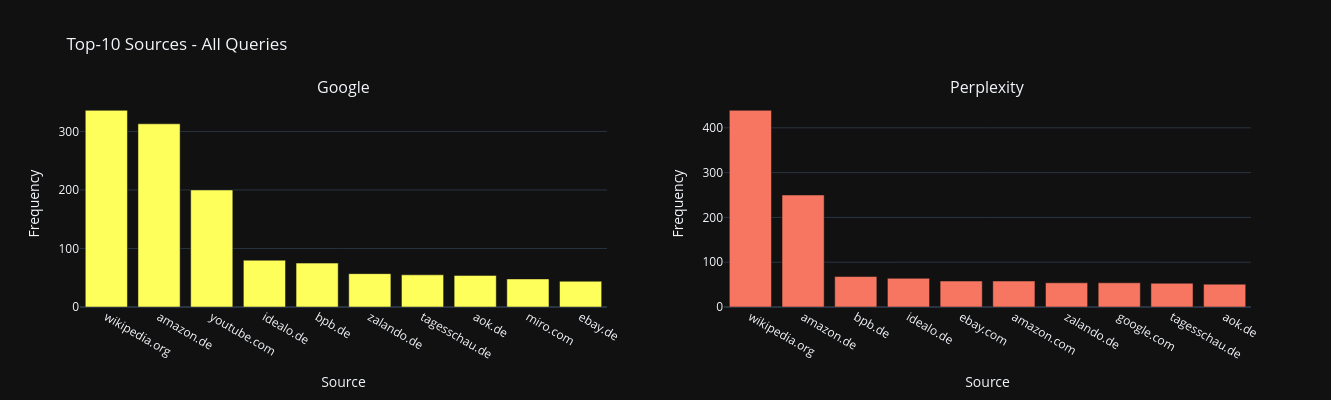
Meistgenannte Quellen: Wikipedia und Amazon dominieren
Anfangs hatte ich ein wenig Hoffnung, Perplexity könnte kleinen Nischenseiten wieder mehr Raum geben. Tatsächlich hieß es lange, Perplexity und andere KI-Suchen würden intensiv auf hochwertige nutzergenerierte Inhalte setzen, etwa aus Reddit oder von Nischenblogs. Tatsächlich dominieren aber Wikipedia und Amazon über alle Kategorien hinweg. Sowohl in Google als auch in Perplexity landen sie auf dem ersten bzw. zweiten Platz der meistgenannten Quellen im gesamten Datensatz. Auffällig: Zwar kann Perplexity bei Vorliegen eines Transkripts auch Inhalte aus YouTube als Quelle heranziehen, allerdings geschieht dies in weit geringerem Umfang als bei Google. Während YouTube bei den meistgenannten Quellen in Google auf dem dritten Platz liegt, taucht es bei Perplexity insgesamt nur äußerst selten auf.
Gute Neuigkeiten für Marketer: Keine großen Überraschungen in Perplexity
Generell liefert Perplexity wenig Überraschungen, wie ich finde. Das sind gute Nachrichten für SEOs und Marketer, da sich die Rankingfaktoren von Google offenbar weitgehend auf Perplexity übertragen lassen. Man muss also nichts weltbewegend Neues lernen. Mich persönlich enttäuscht, dass Nischenseiten ein wenig auf der Strecke bleiben. Ich hätte zumindest Reddit gerne häufiger im Datensatz gesehen, da dort viele hochwertige Inhalte und Antworten auf die unterschiedlichsten Fragen zu finden sind. Vermutlich geht Perplexity hier aber auf Nummer sicher.
Vor diesem Hintergrund gibt es natürlich einige mögliche Verbesserungen an der Analyse. Eventuell werde ich sie später noch einmal mit deutlich mehr Suchanfragen wiederholen, die Suchkategorien diversifizieren oder ich schaue mir einzelne Kategorien wie „Politik“ einmal gesondert an. Mich würde zum Beispiel die Frage interessieren, mit welchen Quellen Perplexity „sensible“ politische oder gesellschaftliche Fragen beantwortet.
Den Code und die gesamten Daten findet ihr bei mir auf Github.
Die Gesamtergebnisse habe ich in einer PDF zusammengefasst.